Until recently, I only had a vague understanding of what GraphQL was. For those that still aren’t sure, please know that it’s ok not to know. There are so many buzzwords and new technologies being created all the time, it would be impossible to keep up with absolutely everything. In fact, it happens so often that IBM even created a chart to document the process that happens each time - this is the hype cycle of emerging technologies:
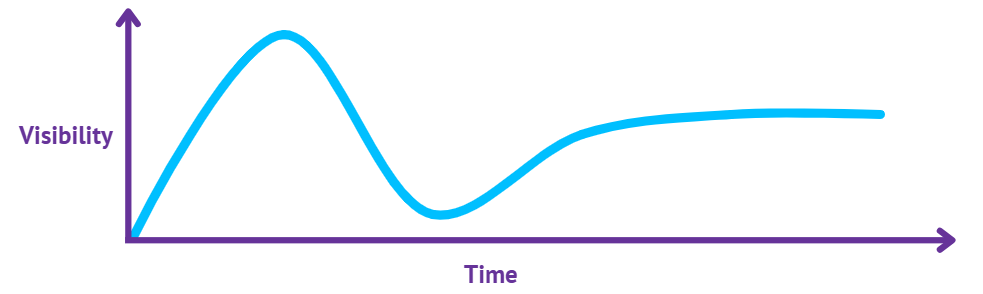
This chart goes through five phases:
- The Innovation Trigger, where the technology is made available to the public for the first time,
- The Peak of Inflated Expectations occurs shortly after, as everyone attempts to apply the technology to resolve every scenario ever,
- The Trough of Disillusionment is when people realise that the technology did not in fact fix everything,
- The Slope of Enlightenment happens as people start using the technology again, but this time with more realistic expectations, and
- The Plateau of Productivity occurs when the technology has found it’s place in the technological landscape and is used in appropriate scenarios.
Currently, I think GraphQL is coming out of the Slope of Enlightenment and starting to head into the Plateau of Productivity, which also means it’s worth doing a refresher for those of us that missed it the first time around.
Why GraphQL Was Created
Back in the distant past of 2012, Facebook was having some issues with its app. At the time it was essentially an adaptation of the website, and compared to other natively built apps it simply wasn’t working as well - so they decided it was time to rewrite it.
Originally they intended to use the existing APIs that they had at the time, which like the majority of the industry were mostly REST APIs.
REST Strengths
- Great when working with simple and less volatile data.
- Has individual endpoints that correspond with its available resources, meaning there’s a nice inbuilt separation of concerns already.
- Having stateless operations means that each request is self-contained, which improves scalability and simplifies the underlying back-end architecture.
- Interfaces well with older systems and technologies, which is great when you’re working with legacy systems.
REST Weaknesses
REST is less effective when working with complex data, such as was required by Facebook to populate the newsfeed. To do so could involve a number of separate REST calls; to get the user’s list of friends, to get the recent statuses made by each of those friends, to get the comments for each of the statuses, to get the likes of the comments of the statuses of the friends…
- Doing so would result in an over-fetching risk as additional unnecessary data would be retrieved unnecessarily,
- Yet it also suffered from under-fetching as all the multiple calls would be required each time the newsfeed is loaded.
- All that additional traffic adds up, and would be especially noticeable on the phones popular back in 2012, which usually only had 1GB RAM.
- Also, all those endpoints from before? Well, any new requirements result in additional endpoints being created, and all the existing ones have ongoing maintenance, including versioning and deprecation.
How GraphQL Resolves This
Instead of traditional approaches, GraphQL works by modelling data as a graph, where data types (like users, posts, comments) are nodes, and the relationships between them (like users posting comments) are the edges connecting those nodes. In this structure, you can traverse between related types, much like how you can move across nodes in a graph.
- Instead of endpoints, with GraphQL it was now possible to use queries (similar to SQL) to specify exactly what data was required for each use case. This nicely solves both the over-fetching and under-fetching issues.
- This increased data efficiency also means it’s more practical for providing real-time data updates.
- You didn't even have to keep building out endpoints for scenarios. For anything with evolving requirements, it became easy to add in fields without breaking previous versions of the query endpoint.
- GraphQL can also return partial data along with error details, which can be useful when diagnosing issues.
This does not mean that GraphQL is perfect for every scenario - there’s a reason why REST APIs are still more common, as shown in the Postman 2023 State of API Report:
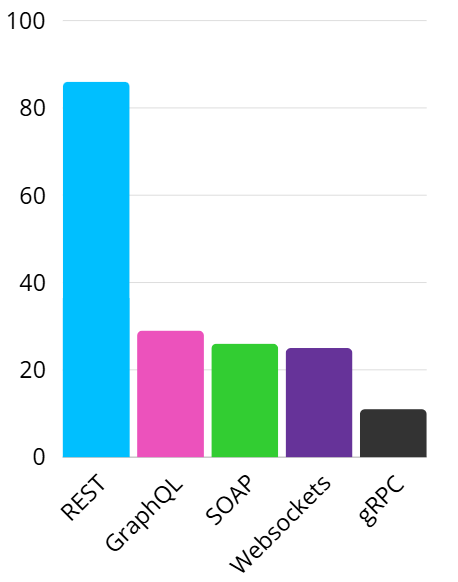
However, if you’re working with complex data and evolving requirements, GraphQL could be the right tool for the job.
Consuming GraphQL APIs
API clients tend to have the same structure:
- Schema representation (retrieved using an introspective query),
- A window for entering your query based on the schema, and
- A window displaying the response.
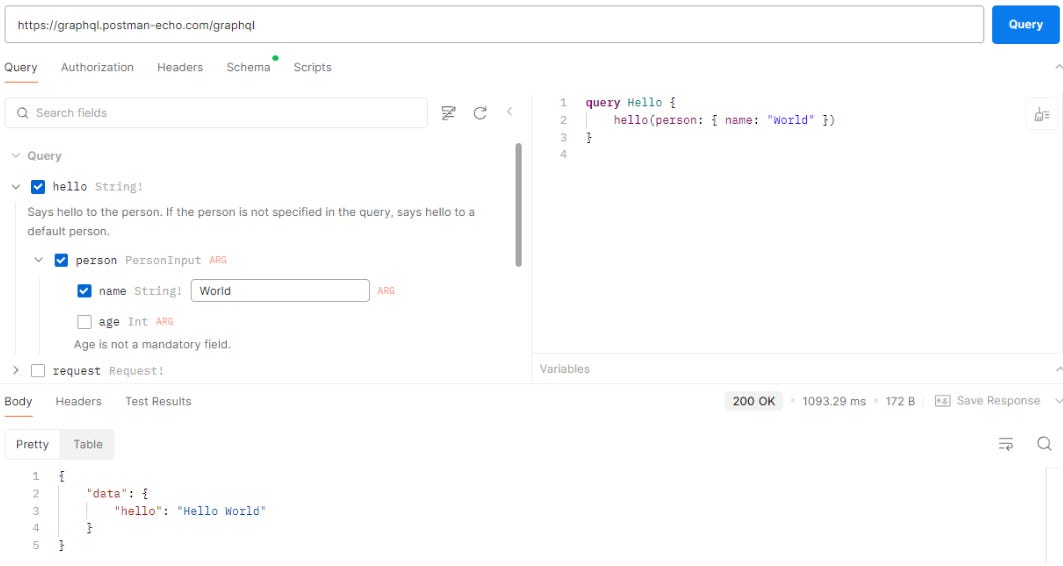
The structure of the response depends on the structure of the query, e.g.
query {
person(personID: "14") {
name
starshipConnection {
starships {
name
}
}
}
}Returns this:
{
"data": {
"person": {
"name": "Han Solo",
"starshipConnection": {
"starships": [
{
"name": "Millennium Falcon"
},
{
"name": "Imperial shuttle"
}
]
}
}
}
}(example from the Star Wars GraphQL API.)
Field names can be altered using aliases, so in the above query specifying
fullname: name
returns
"fullname": "Han Solo"
Directives can be used to add logic based on variables - the following would return the value for model depending on whether fullDetails was true or false thanks to @include:
query ($fullDetails: Boolean!){
person(personID: "14") {
fullname: name
starshipConnection {
starships {
name
model @include(if: $fullDetails)
}
}
}
} Queries can be broken into fragments, the same way that applications are broken into components. If starships and vehicles were derived from an overarching Transport type, the fields within both could be requested like this:
query {
person(personID: "1") {
fullname: name
starshipConnection {
starships {
...vehicleAndStarshipFields
}
}
vehicleConnection{
vehicles{
...vehicleAndStarshipFields
}
}
}
}
fragment vehicleAndStarshipFields on Transport {
name
model
}Which would return in this format:
{
"data": {
"person": {
"fullname": "Luke Skywalker",
"starshipConnection": {
"starships": [
{
"name": "X-wing",
"model": "T-65 X-wing"
},
{
"name": "Imperial shuttle",
"model": "Lambda-class T-4a shuttle"
}
]
},
"vehicleConnection": {
"vehicles": [
{
"name": "Snowspeeder",
"model": "t-47 airspeeder"
},
{
"name": "Imperial Speeder Bike",
"model": "74-Z speeder bike"
}
]
}
}
}
}If we want to do a union on different object types, we can:
query Search($name: String!) {
search(name: $name) {
... on Person {
name
birthYear
}
... on Planet {
name
climate
}
}
}This would return different fields, depending on whether the name was for a Person like “Luke Skywalker” or a planet like “Tatooine”.
Enabling each of these scenarios is driven by the structure of the schema.
Building GraphQL APIs
Schemas
- Mandatory, which also means every GraphQL API is fully self-documented.
- Contains definitions for:
- Data Structures,
- Queries for retrieving data,
- Mutations for modifying data, and
- Subscriptions, for detecting external changes to data.
Resolvers
- Used to ‘resolve’ each field defined in the schema.
- Populates data from a variety of data sources.
- Include four parameters:
- Parent: Result of previous executed resolver. Can also be used as a data source.
- Args: Arguments in the query.
- Context: Shared across all resolvers, contains information such as the users authentication details and database connection details.
- Info: Additional information, useful for debugging.
Security
- Includes wide flexibility in options, and depends on your use case.
- Authentication: Can be done using middleware to intercept the requests before they reach your resolvers. Express-jwt is one example of a library for validating JSON Web Tokens.
- Authorisation: Regardless of which logic used, I’d recommend abstracting it away from the resolvers and having them call the logic as needed. GraphQL Shield is an example of one common way to implement.
- The flexibility of GraphQL can put the API at risk of a denial-of-service attack through overly complex queries that consume all available resources. Mitigate via:
- Complexity thresholds (through libraries such as graphql-query-complexity),
- Depth of query limits (using library graphql-depth-limit),
- Rate limiting, caching, pagination, and any number of other standard approaches to ensure security.
Observability
There are a number of tools available, including Apollo Studio, Prisma, GraphiQL, and New Relic. Each of these is able to track performance and errors as needed.
…But Can We Use AI With GraphQL?
Yes!
AI APIs can be used as a data source, but for using AI in the creation of queries there is GQLPT - where you can leverage AI to generate GraphQL queries from plain text.Summary
GraphQL can be a useful tool, when used in the right scenarios. Use it when working with complex data and evolving requirements, make sure you consider security as you would with any API, and it can be a powerful complement to your other existing REST APIs.